Ever since I was younger, I’ve been bothered by how uneven access to opportunity can be. I didn’t have the vocabulary for it at first. I just knew that where you’re born or how much money your family has shouldn’t dictate your future. This past summer, during my internship at TS Imagine, that curiosity finally found direction.
At TS Imagine, I saw how real-time market data from multiple sources could be aggregated and distributed through blockchain infrastructure, making complex financial information more transparent and accessible. For the first time, I understood how technology could actively lower barriers in finance, not just optimize profits. That experience pushed me to think more deeply about private credit markets, especially in developing economies where small businesses often struggle to access capital.
I began asking a simple question: If algorithms increasingly decide who gets funded, what exactly are they rewarding?
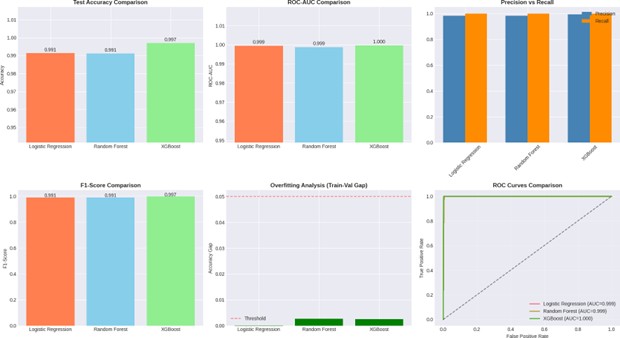
To explore this, I conducted independent research using real-world data from LendingClub, one of the largest peer-to-peer lending platforms. I compared three widely used machine learning models: Logistic Regression, Random Forest, and XGBoost, evaluating both their predictive accuracy and, just as importantly, the transparency of their decisions.
What I found surprised me.
While more complex models like Random Forest and XGBoost offered slight improvements in accuracy, Logistic Regression performed nearly as well, with the added benefit of interpretability. It clearly showed why a loan was approved or rejected. For me, that distinction mattered. In credit markets, opacity can reinforce inequality; transparency can help dismantle it.
research: peer to peer lending
Who Gets Funded? Data, Models, and Access to Credit

Across all three models, one theme was consistent: credit history dominated. FICO scores, prior delinquencies, credit utilization rates, and repayment behavior were significantly stronger predictors of approval than income level or employment length. In other words, consistent financial discipline outweighed raw earnings.
This has practical implications. For small and medium-sized businesses, improving approval odds isn’t about dramatic revenue jumps, it’s about managing debt responsibly, keeping utilization low, and demonstrating reliability over time.
More broadly, this project sits at the intersection of machine learning and economic fairness. It reinforced something I’ve come to believe deeply: technological sophistication should not come at the cost of accountability. If we want more inclusive financial systems, we need models that are not only accurate, but explainable.
As someone who hopes to keep exploring the intersection of economics, computer science, and public policy, this research represents more than a technical exercise. It reflects the kind of problems I want to work on, where code meets consequence, and where thoughtful design can expand access rather than restrict it.